In a previous post, I mentioned that I asked Claude to collect RSS feeds for US newspapers. Here was the prompt:
Create a list of RSS feeds and save them using the following steps:
* Review all of the newspapers linked from this page (https://en.wikipedia.org/wiki/List_of_newspapers_in_the_United_States ), identify if they have a website, and make a list of the RSS feeds available from the website.
* Identify which newspapers do not have RSS feeds
* Identify which newspapers do not have websites
* Create a OPML subscription list of all RSS feeds identified and save this file to C:\Users\sylve\Documents\Claude_Projects\News_Archive
* Create a text file that lists the newspapers that do not have RSS feeds and save this file to C:\Users\sylve\Documents\Claude_Projects\News_Archive
* Create a text file that lists the newspapers that do not have websites and save this file to C:\Users\sylve\Documents\Claude_Projects\News_Archive
* Add the OPML and text files created to a new repository in my Gitlab account called news-archive
The result of this prompt was an OPML file with 386 feed URLs, but only 22 of them had any items. I looked at the first 5 feeds, and saw that Claude had taken the root URL of a site and added “/rss/” to the URL. There was nothing there. Why did Claude do that? Why did it not search on the site to find a valid feed, and if there was none, to add it to the list of newspapers that do not have feeds? If anyone has any insight into this, I would love to hear it.
In a previous post, I mentioned that my first AI project was to develop an application to create a archive of US newspapers based on RSS feeds. I initially used Claude Code to review a list of US newspapers from Wikipedia to search for websites and RSS feeds. As I posted earlier, this took several sessions to complete this task, and I had doubts that I would be able to create an app without hitting my Claude Pro token limit.
My next step was to create a Markdown document describing the app for Claude to use as starting point. I looked at several example product requirement documents (PRDs) and frameworks for developing apps using AI (Get Shit Done, Superpowers) to find a way to get started. Eventually, I decided to follow Peter Yang’s advice on developing apps:
Don’t know what to build? Just tell AI your problems. Ask it: “What are some simple apps that we can build to help me take time back?”
Create a robust plan first. Ask it to “Create a plan with 3 clear milestones” to avoid mistakes during coding. Spend half your time planning with AI.
You’re the manager, AI does the work. Give it feedback anddirection like you would a human employee. Be patient with it
I created a initial plan based on some PRDs I found in Peter Yang’s Github repo. I then asked Claude to review the plan and see if there was anything missing or not clear. Claude responded with a set of 12 things to change and 4 questions before starting any build work – wow! I accepted Claude’s suggestions, provided answers to the 4 questions, and Claude updated the plan (see here).
In the updated plan, four milestones were identified. Claude was prompting me to say “start building milestone 1”, so I did it. Claude then took 10-15 minutes to create code and tests for the Milestone 1 content. I decided to have Claude confirm steps with me as it went, so I could see issues firsthand (and there were issues, but Claude figured them out). If I had “let it run”, it might have finished quicker. During the Milestone 1 work, Claude was able to figure out that I had Wampserver installed on my local machine (which has MySQL, a specified part of the app tech stack), and used that to create the MySQL database for the app. When Milestone 1 development was complete, I did some operations with the app, then told Claude to create a handoff document (handoff.md) in case I hit a token limit during the session.
I then repeated this cycle for Milestone 2, 3, and 4. The handoff document was updated after each milestone. It turned out that I did not encounter any token limit. When the development was complete, Claude then added all of the code/files to a Git repo in the working directory. Here are some screenshots:
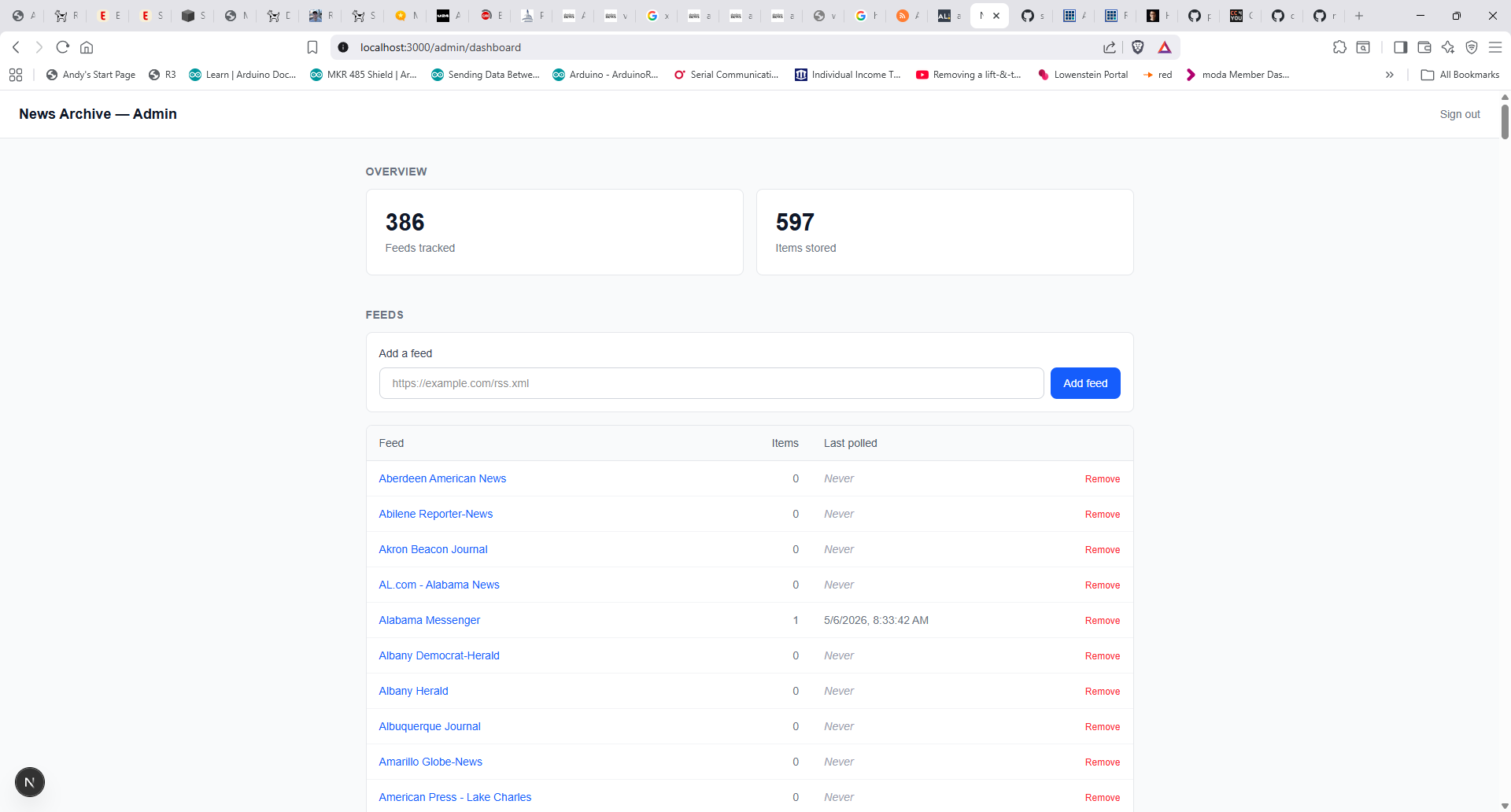
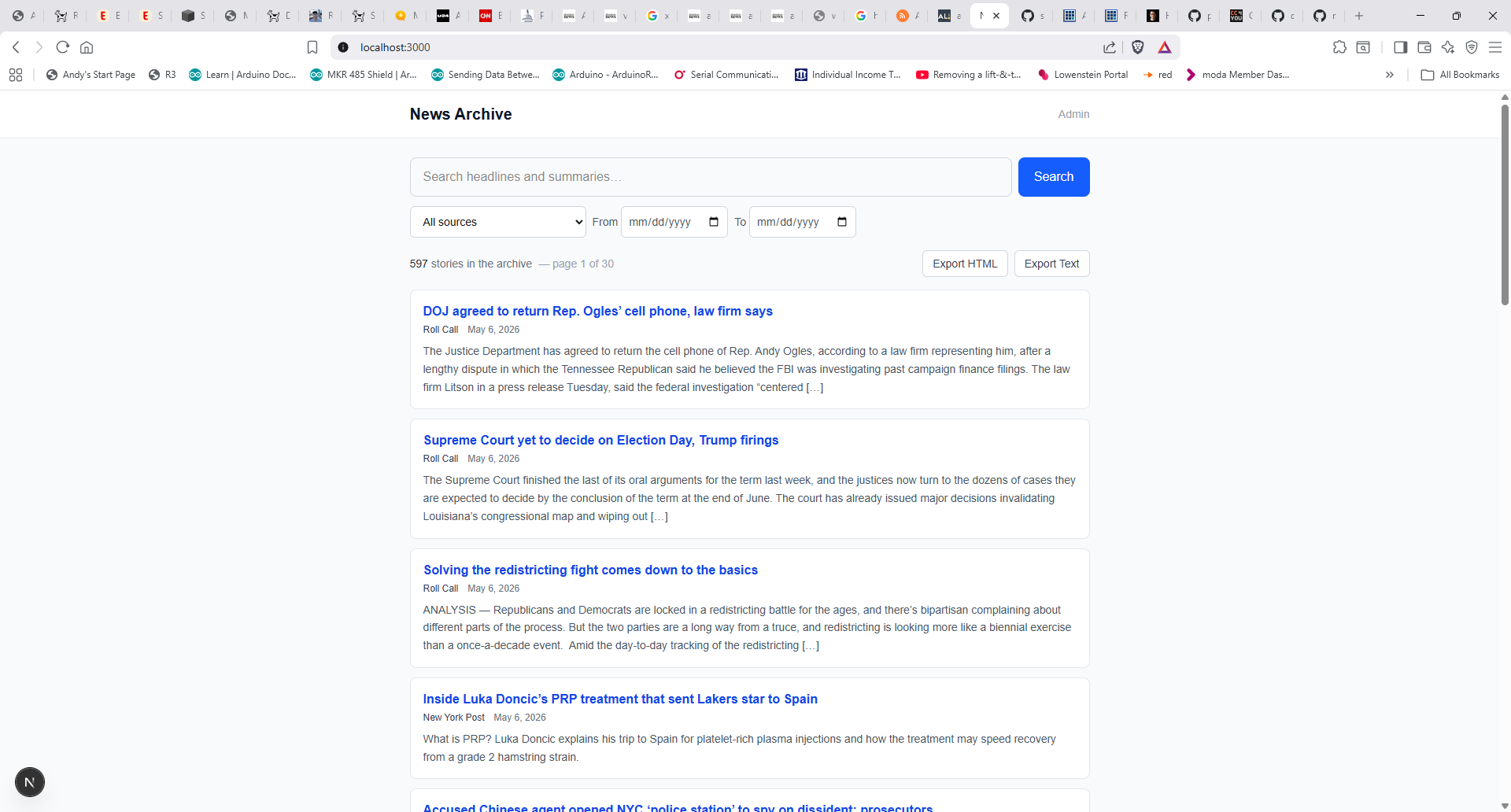
App admin screen
App search screen
To me, this was very impressive. It took less than 2 hours to get to this point – a fully functional application with 79 passing tests – amazing! I will post more when I have a version of the app running on a server.
PS – I have created a new category for these posts (AI for Smart Old Farts), if you want to just read these posts.
In my previous post, I mentioned I started a task to identify RSS feeds for US newspapers. It took three Claude sessions to complete (hit token limit three times before completing the main part of the task). This was a bit of an eye-opener (I have a Pro subscription ($20/month)). Based on that, I am considering trying to run a LLM manually (see this YouTube video for one way to do this). I will post on this after I try it out.
I have watched a number of tutorials on using Claude Code, and I am still working through the Claude Code for Everyone course. After some thought, I have decided on my first project that I would like to develop using Claude. Over the past few years I have been involved in several projects (Portland Protest News, Kamala Campaign Timeline, and Liveblog47) where I was monitoring multiple news sites/feeds for a specific topic. In performing the research for these sites, I spent a fair amount of time reviewing sites/feeds, deciding what to publish, looking for other stories if the sites/feeds I was monitoring did not have what I needed. Having an agent to be able to do this would be a help. Also, it was difficult to research/locate other stories that were not current (published in the last day or two).
I am going to start with creating an application to collect stories/posts based on RSS feeds and create an archive of news for the United States. Next, I will provide an interface for researching that archive. I am starting with collecting RSS feeds for newspapers and news media sites within the US. This will probably take a bit of time (already ran out of tokens in my current Claude session), but it will give me time to plan out the next steps.
If anyone is interested on collaborating on this project, let me know!
The new Blurt theme on WordPress.com does not “use RSS to glue” any systems together – it is a WordPress theme, and supports RSS because RSS is built into WordPress. It “looks like Twitter”, but each post is a standard WordPress post. Any other questions?
This morning, Dave Winer published a long post about the new Blurt theme available on WordPress.com. He comments on how this theme competes with his WordLand application, which provides a streamlined editor interface for WordPress blogs, saying “…most of the things it advertised for were very much part of the pitch for wordland.” I am sorry to have to bring this up, but there are a lot of features within WordLand that are not a part of this theme, so this is a poor comparison. There are also many other issues with this post, so let’s get started with a review.
I created a test site to see what the editing interface was like. My first impulse was to click on the “plus” sign at the top, since that is an accepted WordPress shortcut to add a new post. This action brought up the familiar WordPress Gutenberg editor user interface. I typed a short phrase and posted it. The look and feel of posts published on the theme is very similar to Twitter. It also offers a comment text box for reader to add comments.
Next, I decided to explore the menu on the left side of the site. The Compose link brought up a familiar posting interface (i.e., “just like Twitter”). I entered a test post there. I then created another test post to see if I could do any linking or styling of the text, but I could not. This is a key feature of WordLand, so points to Wordland here. So – better editing experience with WordLand, ability to post like on Twitter with Blurt. It’s difficult for me to see how Blurt competes with WordLand.
On the Blurt topic, Andrew Shell says this was a theme put together by two WordPress developers in a week as part of an internal WordPress project called “Radical Speed Month”. From Dave’s response, I assume he does not know the developers and/or has not worked with them, since he did not know this new theme was coming. So what? Who cares? Go do something better, or different!
The majority of Dave’s post complains about how Automattic should have worked with him on this Blurt thing, and on his WordLand project, and how they should act as a “banker and distributor“, and not compete with developers on product development. My response – why should Automattic be working with him and providing him development support, or anyone else for that matter? They are an independent company with their own goals and directions. From historical items in his post, Dave recounts a number of examples where he developed a product and the “platform vendor” built something on his ideas, or did not work with him. Again – so what? Who cares? I think Dave should take a look at this Jason Alexander video talking about actors waiting for someone to hire them, and replace the word “actor” with “software developer”. Go build out the vision for WordLand that you wrote about in September 2025. We’ve been waiting for eight months, where is it?
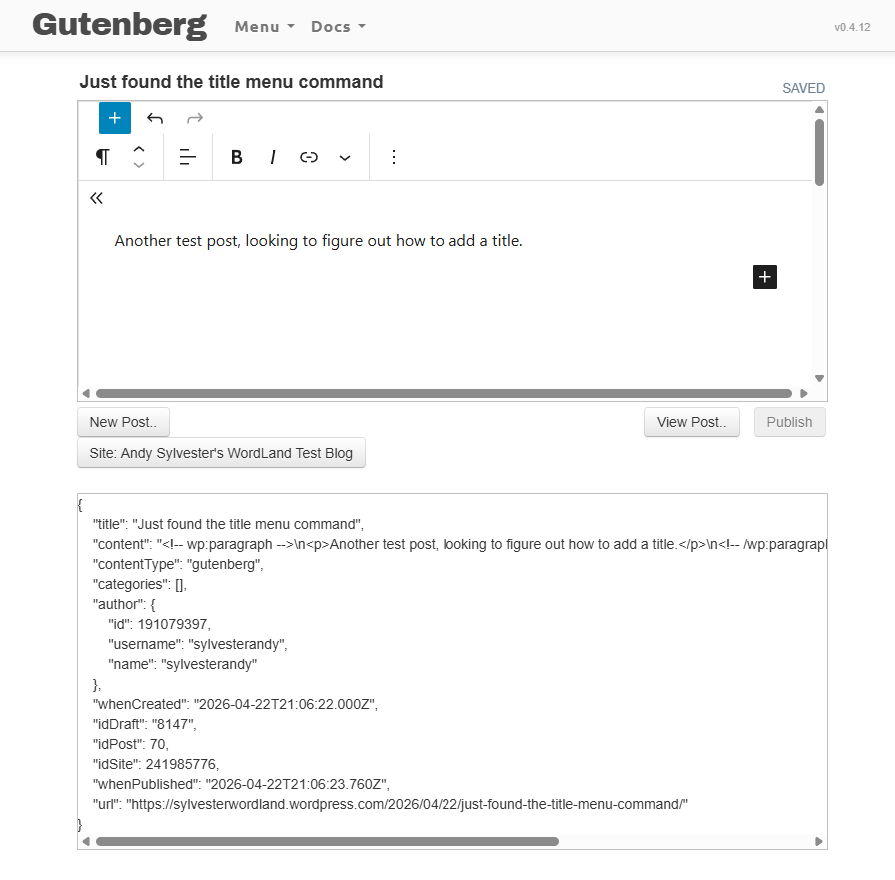
On April 12, 2026, Dave Winer announced a demonstration version of a second editor (GutenbergLand) integrated with the wpIdentity package that powers Dave’s WordLand editor for WordPress.
The editor allows you to add blocks like when using the native Gutenberg editor in WordPress.
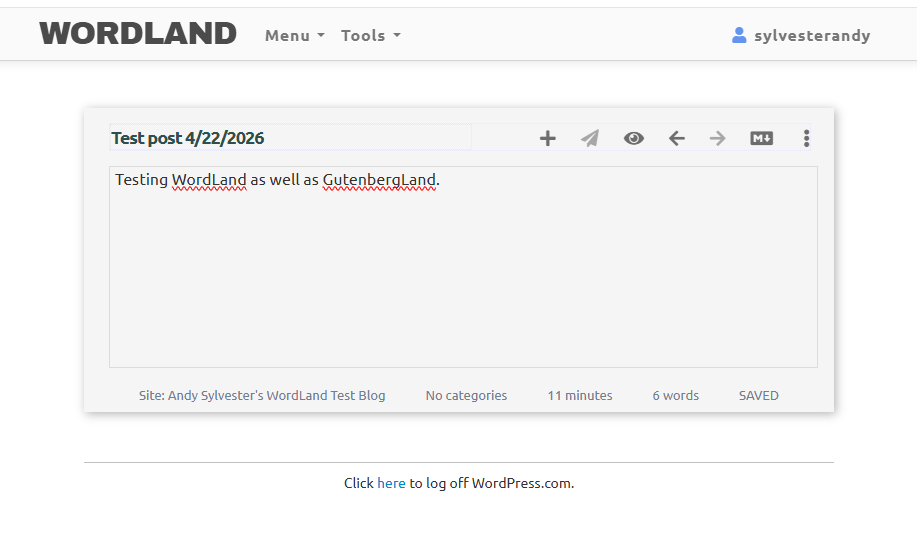
Here is a screenshot of WordLand for comparison:
I was able to select my WordLand test blog as the location for my GutenbergLand post, and was able to post some text, then another post where I added a title. In WordLand, a title can be added to a post in the editor user interface, but in GutenbergLand, the title has to be added via a menu command.
From a basic editing standpoint, I would say either editor can be used for creating WordPress posts on WordPress.com sites. Some setup is still required to be able to post to WordPress self-hosted sites (Jetpack plugin is required, see this Github issue).
Now that I am retired, I am taking some time to explore AI tools, specifically Claude from Anthropic. In my previous job, I used Google Gemini for answering questions on tool setup/options, or creating short one-off scripts for repetitive tasks. However, these were all performed using ad-hoc prompts, and I wanted to learn how to use CLIs to create things.
I signed up for a Claude Pro subscription, and started a free course called Claude Code for Everyone (created by Carl Vellotti). The first module was an overview of how Claude can analyze files, extract and summarize data, and several other features. The second module was a first step at “vibe coding” – creating an online quiz. Claude created the code, added a repo to my Github account, then deployed it to Vercel (see the quiz here). In many ways, this is a contrived example, but a good way to get my feet wet with this kind of tool. Now I need to think of some apps to create!
As I mentioned in a previous post, I am now retired. As I approached my first week of retirement, I had been making a list of things I wanted to do. As my list grew to 25 items, I felt a little uneasy. I needed some more structure…and that is when I turned to org-mode in Emacs.
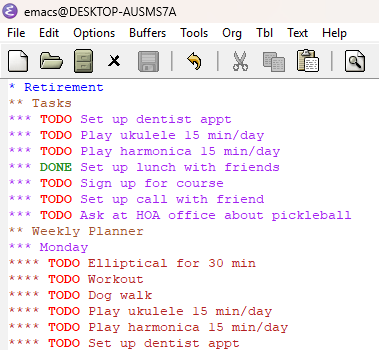
I created an outline with the first level heading of “Retirement” so I could find it easily within my main org file. I then added two second level headings (Tasks and Weekly Planner). The Tasks heading is the “inbox” for when I think of something new that I want/need to get done. Under the Weekly Planner heading, I added sub-headings for each day of the week. Within each day, I had a standard set of tasks (exercise, dog-walking, practicing musical instruments). I then chose a few items from the Tasks list and copied them to the days in the Weekly Planner. As I complete the tasks (TODO items in Org Mode), I change them to DONE, and moving items up and down in the list depending on my priorities. Finally, I have a “Log” heading where I record significant things for each day (PS – I already that this in my org file).
Here is a screenshot with example tasks:
On Monday, I started using this system. Today (Thursday), I would say it is working well for me. Yay! I have created a sample file if anyone want to try this. Enjoy!