
Dave Winer again calls for “a twitter-like system built with feeds, with all their limits”. In May 2023, I created My Status Tool (Github repo) using Node.js that provides the basic posting and reading functionality within Twitter, but using RSS and rssCloud as the enabling technologies. Colin Walker also created a PHP implementation (Github repo), and our two versions were able to interop. Dave also called for this back in December 2023 (my response), but from what I heard, Dave had some other ideas besides working with MyStatusTool. I don’t think that FeedLand is the system he was talking about, and I don’t think that Blogroll Social is the system either. Anyone interested in working on this?
Software Development
There are 108 posts filed in Software Development (this is page 3 of 11).
Setting up WAMPServer in 2024
I have been wanting to try out some PHP scripts for posting to a WordPress site from Ton Ziljstra (see this page for background, and Github for the scripts). I have a Windows laptop, and have used WAMPServer on previous laptops so I chose WAMPServer (download link). I noticed when I started the install that there were some Visual C redistributable files that also needed to be installed (see bottom of this page). I went to the release page and downloaded the latest version of the VisualCppRedist_AIO_x86_x64.exe file and used “Run as administrator”. This application installs multiple Visual C executables, and takes several minutes to run. You will see a number of windows open and close. When the installation is complete, there will be a splash screen indicating that all files have been installed. This might be behind other windows, so you may want to monitor the icons in the Windows app tray at the bottom of the screen to see if there is an icon you do not recognize.
After the installation, it is a good idea to run this checking app to confirm that all necessary Visual C files were installed correctly. I ran this and got the message that all installations were complete.
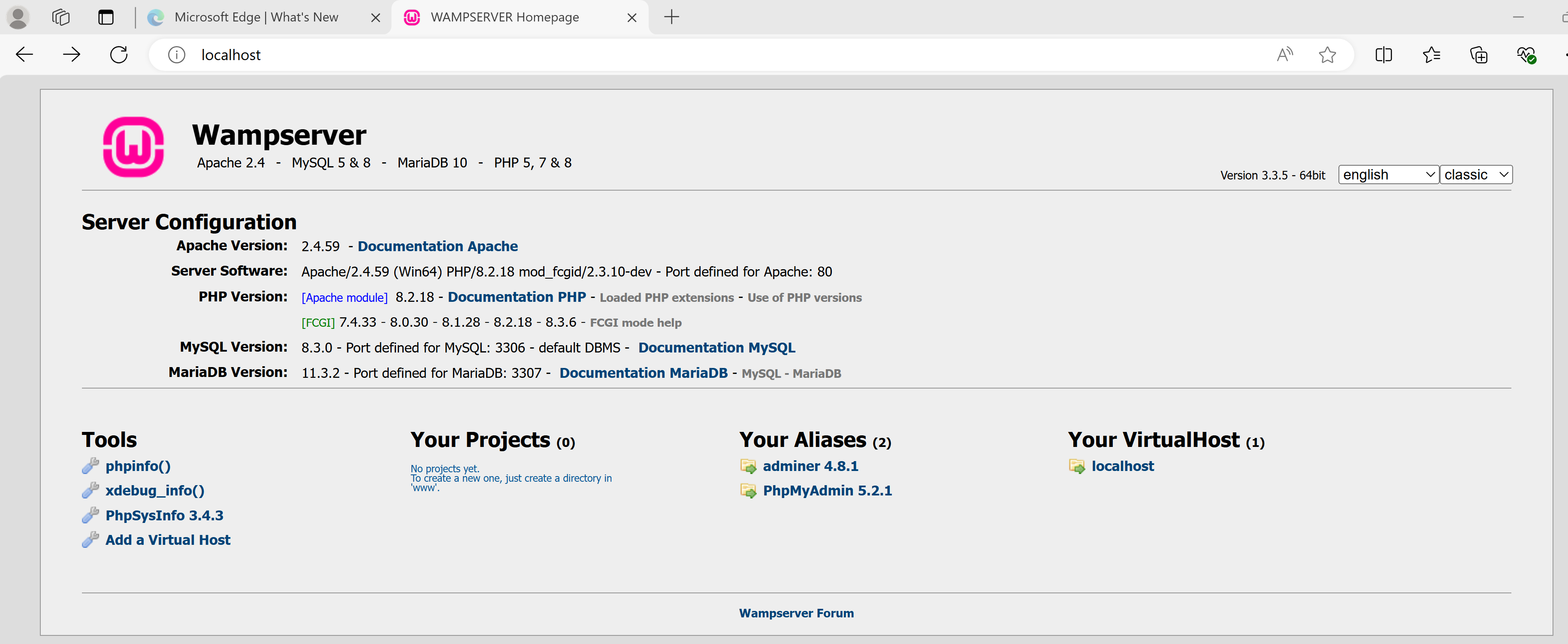
Finally, I started the WampServer installation by double-clicking on the EXE file I had downloaded to start. There are several checkboxes to accept the license, the location of the installation, and default web browser and text editor, but other than that, the installation took care of itself. To start WAMPServer, I double-clicked on the icon on my desktop (titled “Wampserver”). A splash screen indicated after 10-15 seconds that all server apps were running. I started Microsoft Edge and typed “localhost” in the address text, and got a “main screen” with info on the server apps.
Finally, I wanted to create a test PHP file to make sure that the server was working. I used the following source code:
<!DOCTYPE html>
<html>
<body>
<?php
echo “My first PHP script!”;
?>
</body>
</html>
I saved this in a file called hello.php, and copied it to C:\wamp64\www. I then changed the URL in the browser to localhost/hello.php and saw the following:
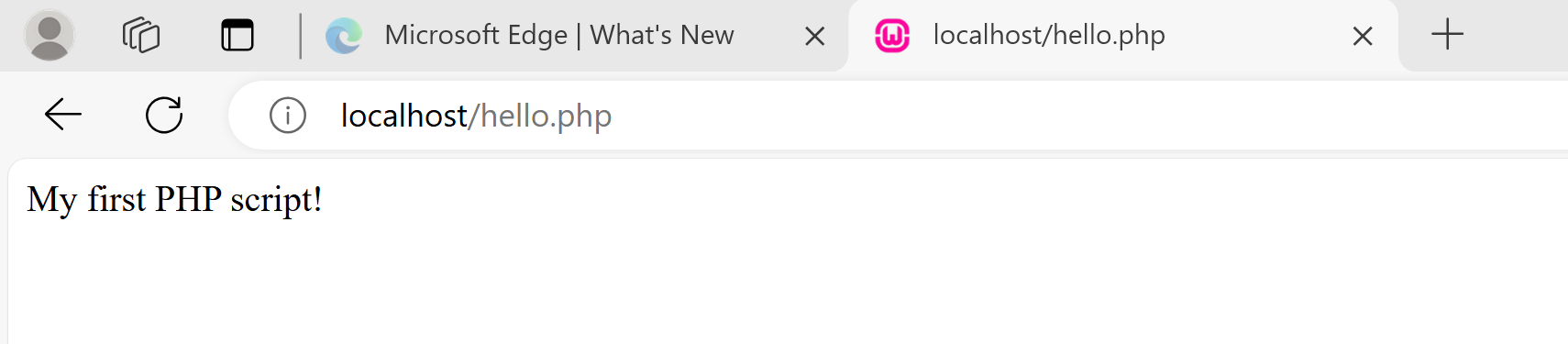
Now I am ready to start doing some PHP testing!
While looking for some testing resources, I found a nice introduction to test-driven development by James Shore. His Github repo contains a test environment for Node.js and Javascript, but I think the key feature are the five videos linked from the repo. Also, they are part of a larger video site that used to be a subscription site, but is now free to all. Awesome!
Terrance Eden: ActivityPub Server in a single PHP file (via Simon Willison)
Co/Recursive: Beautiful Code – Inside Greg Wilson’s Vision for Software Design –
Greg Wilson has been on a decades-long quest to transform how we teach and talk about software design. From getting rejections for using the term “beautiful code,” to empowering scientists through workshops on Python and Unix, Greg has pushed to bridge the gap between theory and practice.
Join us as Greg shares his failures and epiphanies along the way. You’ll hear how he revolutionized research computing by showing physicists the power of profilers. How he taught grad students the elegance of shell scripts. And how he’s crusaded to create a shared language to discuss software architecture with the nuance of true craftsmanship.
Greg’s captivating journey reveals that with perseverance and the right examples, we can elevate software design discussion to an art form. But that we’ve got a long way to go. You’ll come away enlightened and eager to level up your own understanding of software design.
Software Unscripted: Programming and Industrial Design with Greg Wilson – Richard talks with programming teacher Greg Wilson about different types of beginner programmers and how they learn most effectively, what counterintuitive aspects of programming languages they tend to find more or less difficult to learn, and about the surprising relationship between software architecture and industrial design.
The topic of text boxes
Recently, in another post on the subject of textcasting, Dave Winer made a comment about text boxes:
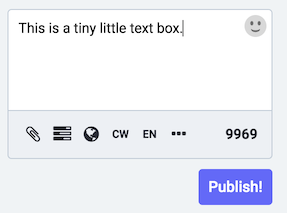
Every time you see a tiny little textbox that’s a sure clue they’re trying to own you, and hoping you don’t notice.
http://scripting.com/2024/02/01.html#a154043
{kind=link}
I think this is a reach. In my opinion, the simplest reason to use a text box for text entry is that users are used to it and it is easy to implement (using Occam’s Razor here). Another explanation is that it is use of prior art, as Dave Winer has written about before (see here, here, and here). No sinister plan to “own” anyone here. Could text editors be better/have more features? Sure they could! Could writing apps cooperate with each other and have APIs? Sure they could! Should people be demanding these things? Sure…maybe….or maybe they could make those things happen…or maybe they could submit a feature request….
If the software is open source (Mastodon et al), someone could make their own changes. If the software is a service provided by a company that does not charge for the service (hmmm…Twitter, Facebook, Threads, Bluesky come to mind), it seems more difficult for users to request features and drive changes. If a group of users REALLLY wanted something and no other app seemed interested, maybe they could create their own product (thinking Kickstarter here). To me, it comes down to this: how bad do you want this?
Finally, another take on this sentence comes from Ken Smith:
Based on Ken’s comment, I take this as “any antisocial behavior” in the blank – racism, anti-Semitism, discrimination, manipulation…the list can go on and on as Ken points out. This Quora thread has some good points about someone trying to “own” someone.
Sacha Chua: Emacs tweaks: Choosing what to hack on – I liked this post a lot, showing Sacha’s process for working on her Emacs setup, and providing some insight on hacking in general.
Darek Kay: Style your RSS feed – tutorial on using XSL(T) for styling a RSS feed (via Sacha Chua)
I-Programmer: Review of “Software Testing Strategies” by Matthew Heusser and Michael Larsen.